Summary: in this post I demonstrate how you can interact with locally hosted LLM models in R using the ellmer package and LM Studio.
If you didn’t guess already, the title of this post was suggested by a Large Language Model (LLM). The bartowski/Llama-3.2-3B-Instruct-GGUF LLM to be precise. Unfortunately for you, the rest of this blog will be written by me.
Intro
If you’ve connected with me on Bluesky or Linkedin you’ll know I think the benefits and impact of Artificial Intelligence (AI) are frequently exaggerated. With companies increasingly trying to shove ‘AI’ features into their products to satisfy executives that have no idea how it works. But, you’ll also know that I’m not blind to their utility, being a frequent user of Claude and ChatGPT for refining code, steel-manning methodologies and improving my writing. In fact, I wrote up a guide on how I use ChatGPT early in the AI craze.
Which is why whenever I show others how to use AI tools, I spent an inordinate amount of time making it clear what they can and cannot do (noting we’re still figuring this out). Let’s just say I’m ‘skeptically enamored’ by the technology.
Interacting with LLM models in R
A LLM is a type of machine learning model that can be helpful for natural language processing and generation tasks. Although they can be useful for a variety of tasks, I frequently employ them when I need to generate a set of boilerplate text, clean unstructured data or extract information from a document. I’ve therefore been trying to intelligently integrate LLMs more directly into my R workflow.
Unfortunately, this requires tapping into an LLM’s Application Programming Interface (API). Fortunately, tapping into APIs is possible in R. Unfortunately, this frequently requires interpreting poorly written developer document and wrangling JSON data.

But, fortunately you won’t have to suffer like I did thanks to Hadley Wickham and the team behind the the ellmer package. To learn more about the package’s capabilities check out the github or tidyverse page, but in essence it greatly simplifies interacting with the most popular LLM models.
The problem
I’ve been interacting with LLMs in R a lot recently, as I’m building an analysis pipeline that requires extracting metadata from unstructured text documents. I’ve mainly been using Anthropic’s Claude model as I find it to be more reliable than its competitors. However, the API request limits can make building a new analysis pipeline cumbersome.
The solution(?)
Although I could just try to make less requests of Anthropic’s API, the problem seemed like as good an excuse as any to figure how to deploy a local LLM model that could serve as a temporary substitute until the pipeline is working. Once everything works I’d then switch back to using Claude.
LM Studio
LM Studio is an application for downloading and running LLM models locally. Although it’s ‘free’ for personal use, there are limits if you’re using it for commercial purposes (see: terms of service). You can download the latest version of LM Studio here.
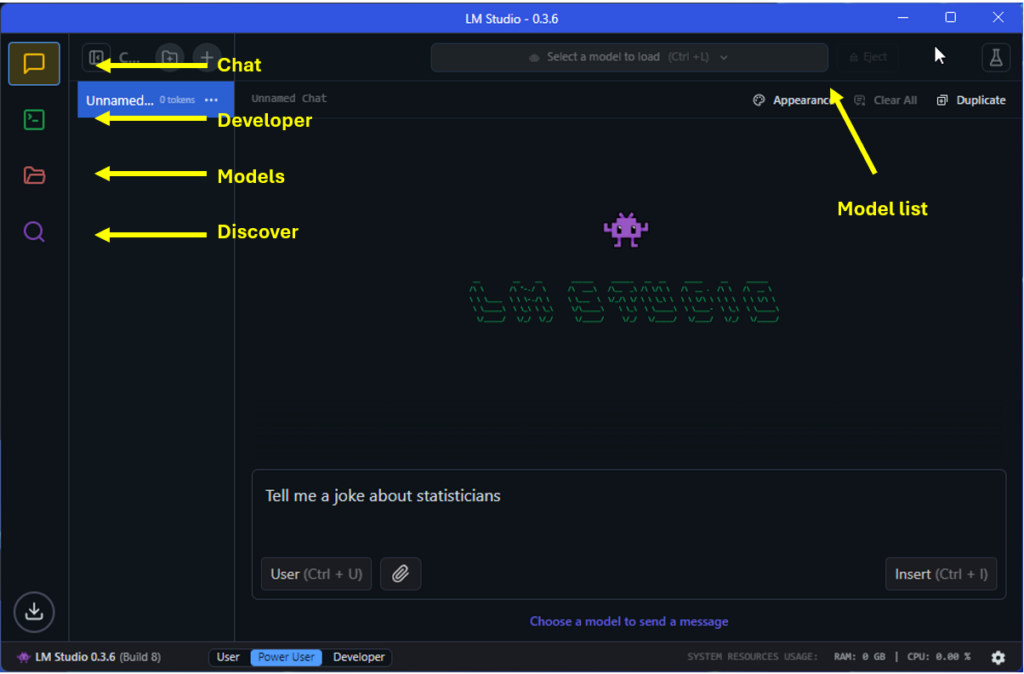
When you first open LM Studio you should see a screen similar to below (without the annotations). The the areas of the app we’re interested include:
- Chat: a chat style interface for interacting with models we’ve downloaded.
- Developer: options for setting up a local server for interacting with a model.
- Models: lists models you’ve downloaded and provides an interface for altering model defaults.
- Discover: provides an interface for finding and downloading models.
- Model list: for selecting a model you’d like to load.
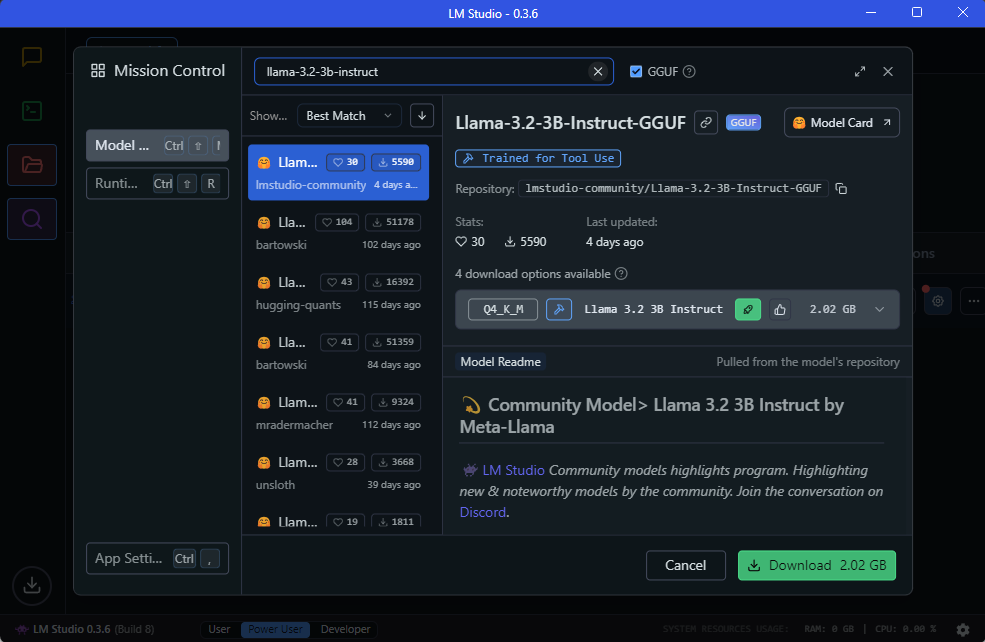
Finding and downloading a model
Once you’ve installed LM Studio, you’ll probably want to download an LLM model. For our purposes we’ll go with a small version of Meta’s Llama model, which you can find by searching for ‘llama-3.2-3b-instruct’ via the ‘discover’ menu in LM Studio:
(You can also check out Hugging Face’s leaderboard for a ranking of open LLM models).
Loading and interacting with a model
Once you’ve downloaded the model, there are a number of ways to interact with it. The simplest way is to loaded it via the dropdown menu and chat with it directly using the ‘Chat’ panel:
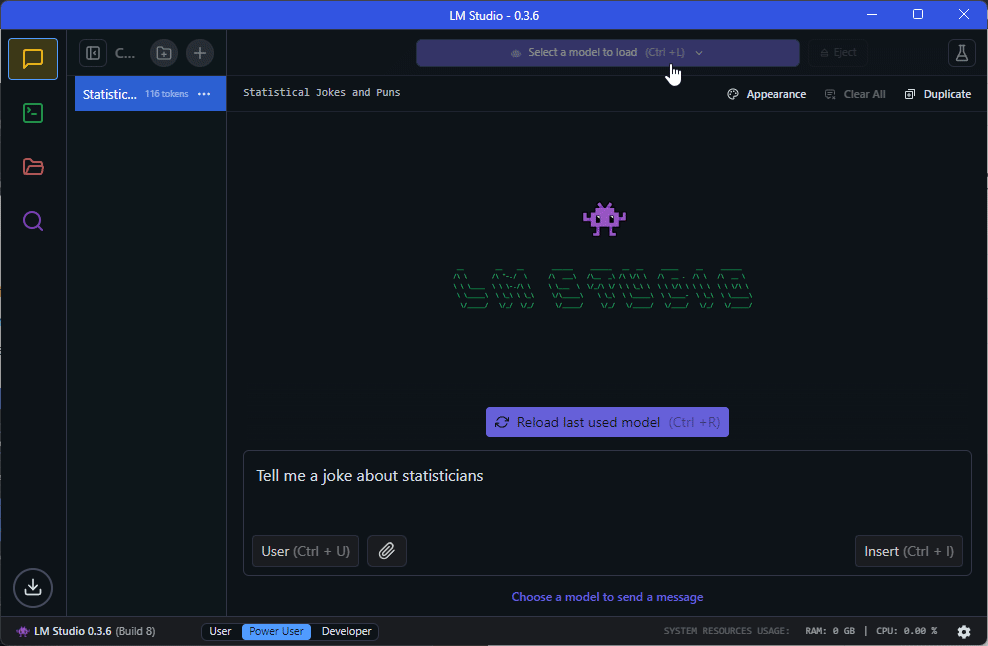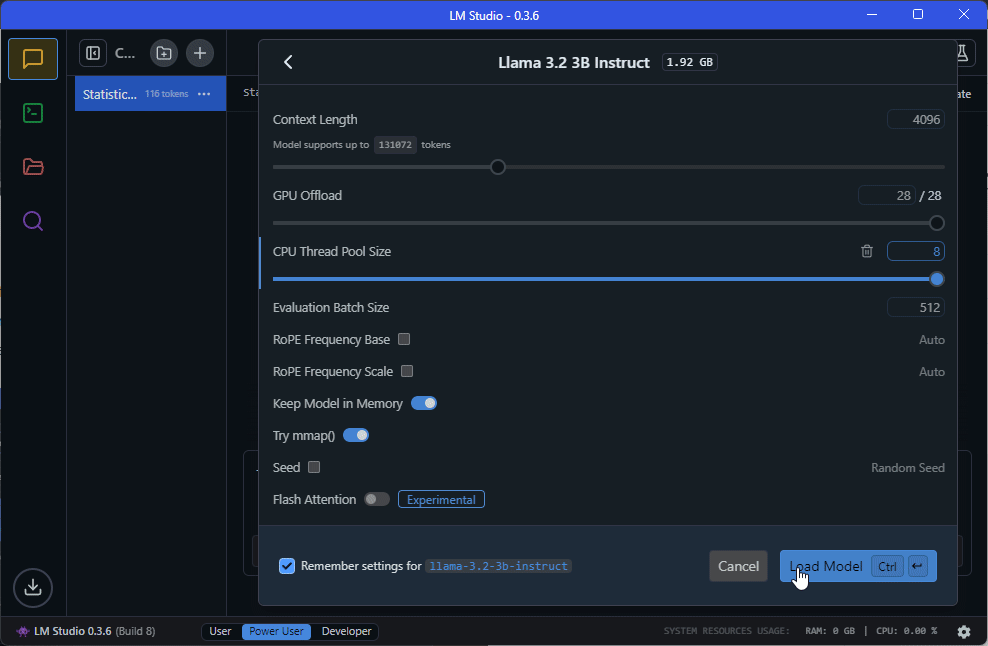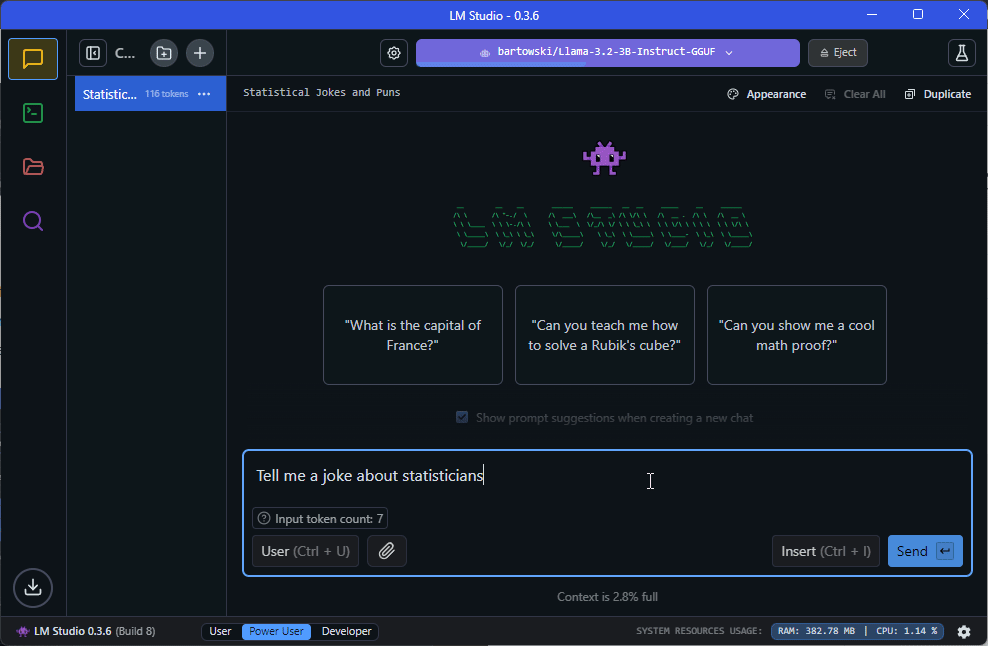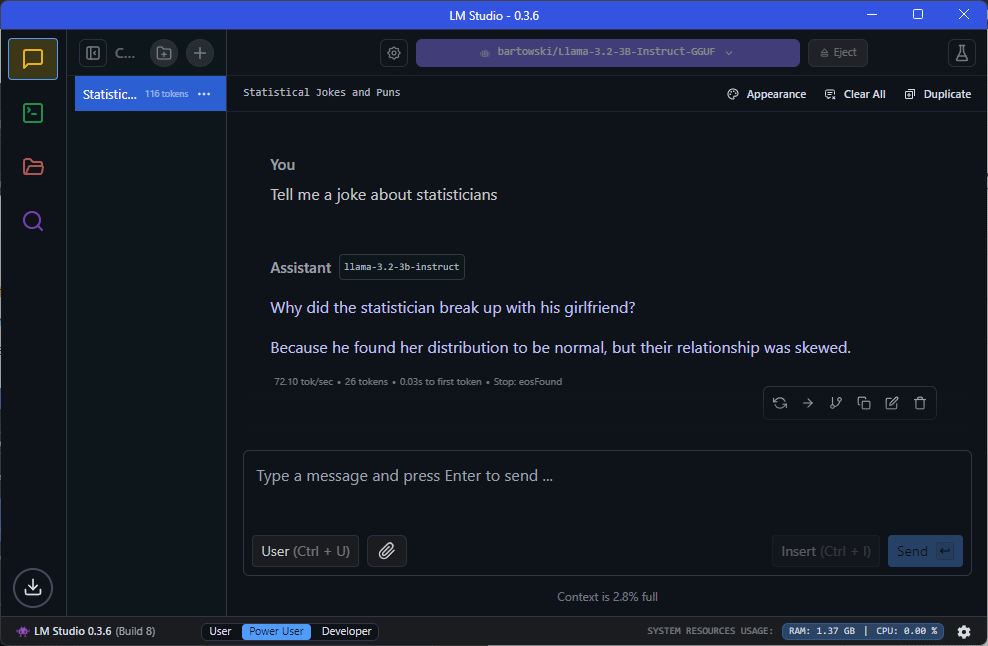
Setting up a local LM Studio server
As useful as having an endless supply of bad jokes is, we’ll have to cover this in a later post. Our focus today is setting up a local server that we can access in R.
This is embarrassingly simple and requires navigating to the developer tab, loading the model using the drop down menu and starting the server by toggling the switch on the top-left. Pay particular attention to the information in the ‘API Usage’ panel as we’ll refer to this when we interact with the server in R.
Note: I’ve set the seed to ‘123’ when loading the model. I’ve also specified a temperature of ‘0’ in the model settings (see: ‘My Models’ > llama-3.2-3b-instruct > ‘Edit model default config’ > Inference > Temperature).
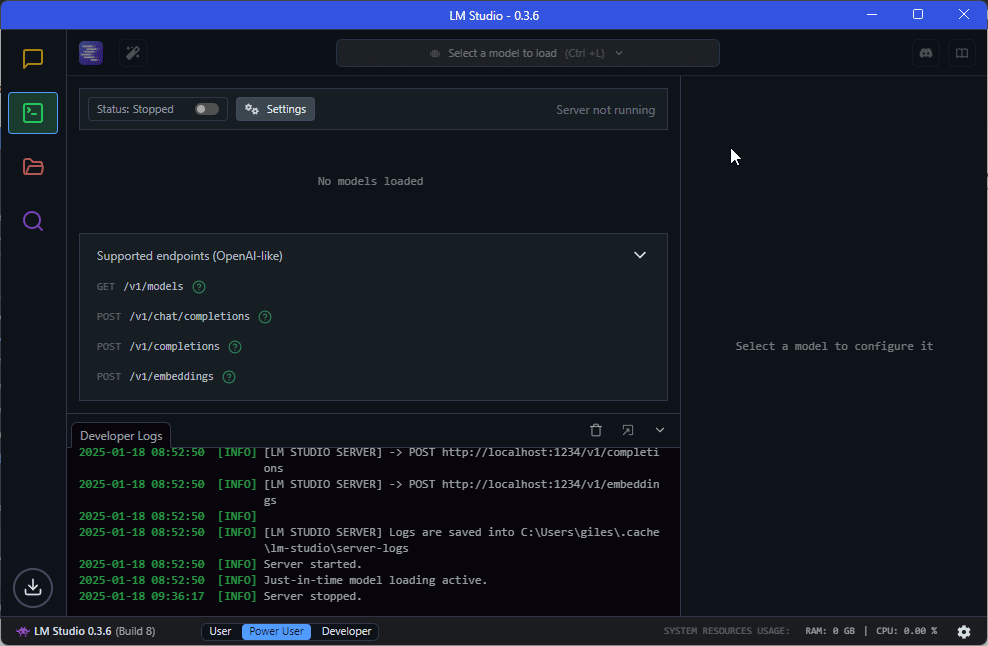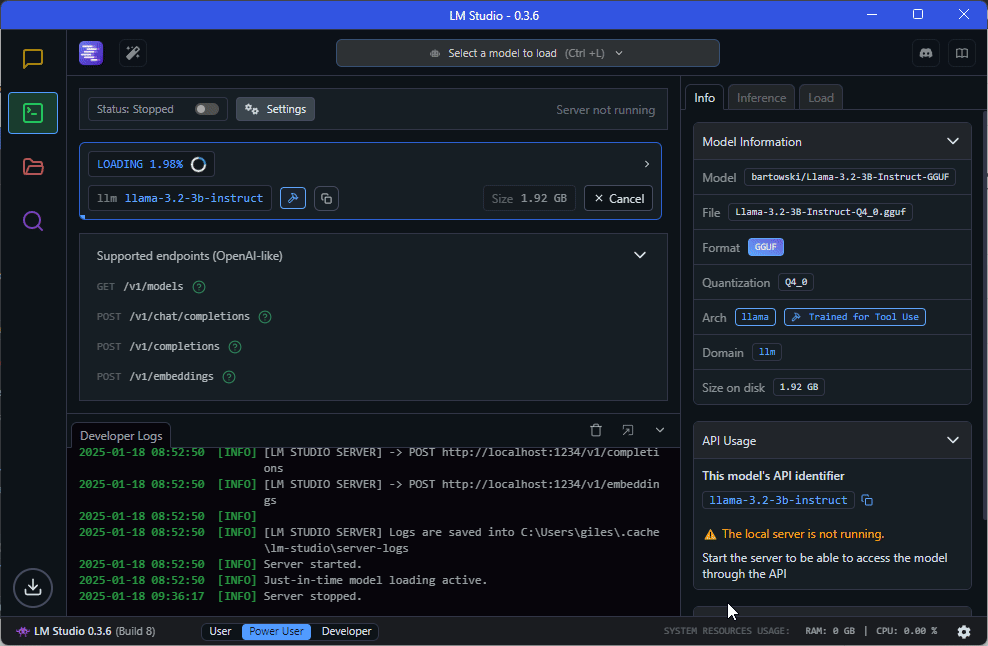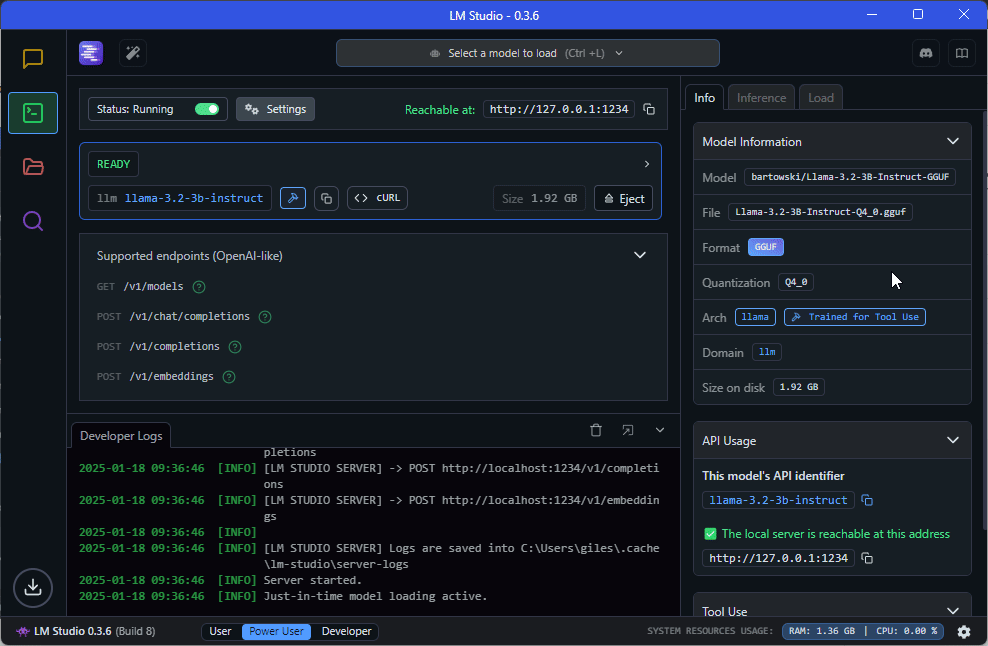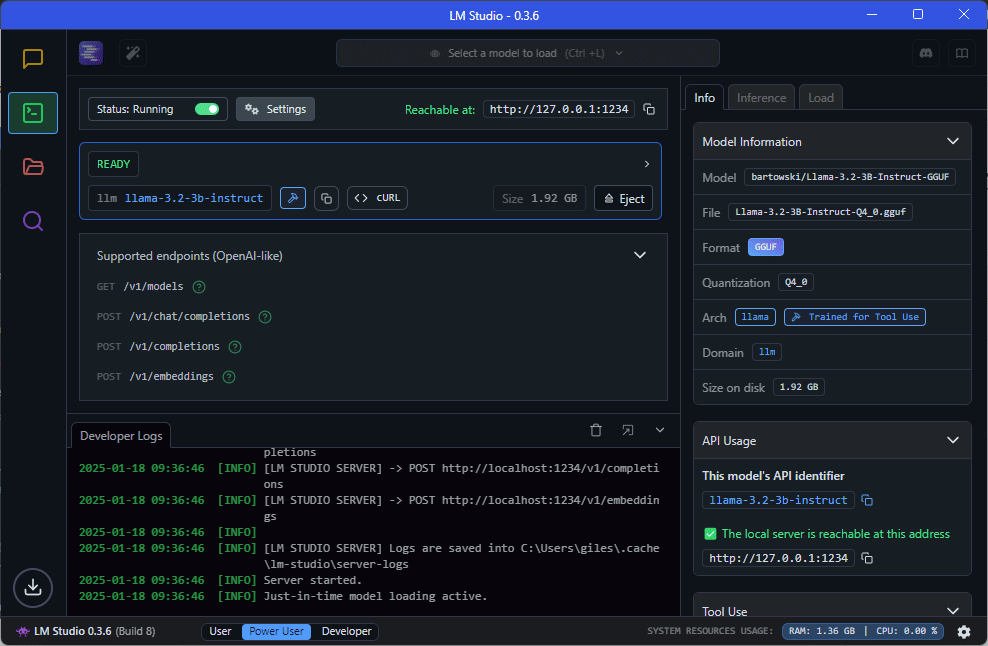
Interacting with LLM models in R
If you’ve made it this far you should have an LLM model running in the background. To interact with it, we’ll be using the ellmer package which can be installed using install.packages(‘ellmer’). I’ve mainly been using ellmer to interact with Anthropic’s Claude model, but the package supports a variety of functions for specific providers such as OpenAI, Groq and Google Gemini (see here).
We’ll be using the chat_vllm() function which allows us to connect to our LLM server, but the basic setup is similar: you setup a chat object that specifies the default system prompt, the model to use and your API key. For the chat_vllm() function we’ll also need to set the base_url so it knows the address of the server.
In the code below, after loading the required packages, we’ve specified key inputs required by the chat_vllm() function. Notice that the values of the base url and model are directly sourced from LM Studio in the ‘API Usage’ section of the developer panel. The API key is simply ‘lm-studio’ as per the documentation.
For the sake of providing a reproducible demonstration of interacting with a local LLM in R, we’re going to have it complete a really simple task that we don’t need an LLM for: take a string of numbers separated by ‘,’ and return them as a string separated by ‘;’.
These instructions are specified in the system prompt in ref_prompt (we’ll generate the numbers below). Notice that the prompt specifies to the LLM that it should not comment on the output. This is a great demonstration of how LLMs can be quirky to work with, as you need to be really explicit about what you want. In this case, I’ve included this line to avoid the model sharing its life story when returning the string of numbers we’ve asked for.
Code: Getting ready for some localized AI “fun”:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
#load packages library(ellmer) library(tidyverse) #set assumptions ref_llm_url<-"http://127.0.0.1:1234/v1/" ref_model<-"llama-3.2-3b-instruct" #specify prompt to provide LLM ref_prompt<-c("Output this data as numeric string using ';' as the deliminator. Do not comment on the output:") #set up chat object fnc_chat<-chat_vllm(base_url=ref_llm_url, api_key= "lm-studio", model=ref_model, system_prompt = ref_prompt) |
One thing you might notice when running this code is that the chat_vllm() function hasn’t interacted with the server yet. Instead, we’ve saved it as an R6 object which we can interact with by calling the ‘chat’ method. You can read more about this on the Github page, but one advantage of this approach is that previous conversations are saved. For instance, once we’ve called the chat method below, results of the conversation are stored in ‘last_turn()’.
The code below sets up the example by creating a data frame with a series of 100 random numbers in the source_data column. I’ve set the rounding to nine to reduce the chance we’ll encounter floating point errors when comparing the output produced by our LLM model with the source data.
The prompt and data is then sent to the local LLM via fnc_chat$chat(). Results of the conversation have been saved under dta_llm_reply and converted to a variable in the dta_rnorm data frame. But, if you look at dta_llm_reply you’ll see what was returned by the model – a string of numbers separated by ‘;’. Because we specified not to comment on the output it also didn’t provide us with narrative information about the task, which is handy as we’re just interested in getting the string of numbers.

The final line of the code simply demonstrates that the previous interaction is saved in the fnc_chat under $last_turn.
Code: Starting the conversation:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
#generate a random string #(I've rounded to avoid a floating point errors) set.seed(123) dta_rnorm<-data.frame(source_data=rnorm(100)) |> round(9) #send prompt to local LLM model and save results dta_llm_reply<-fnc_chat$chat(paste(dta_rnorm$source_data))[1] #save results from LLM as a column in dta_rnorm dta_rnorm<-dta_rnorm |> mutate(llm_transcribed=dta_llm_reply[[1]] |> str_split(pattern=';') |> unlist() |> as.numeric()) #show last conversation fnc_chat$last_turn() |
Once again, there really is no reason you would use an LLM for a task like this. After all, if we really needed to complete such a simple task we could just use str_replace(). But, it does provide a simple illustration of how to interact with a local LLM model in R.
Code: Checking its work
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
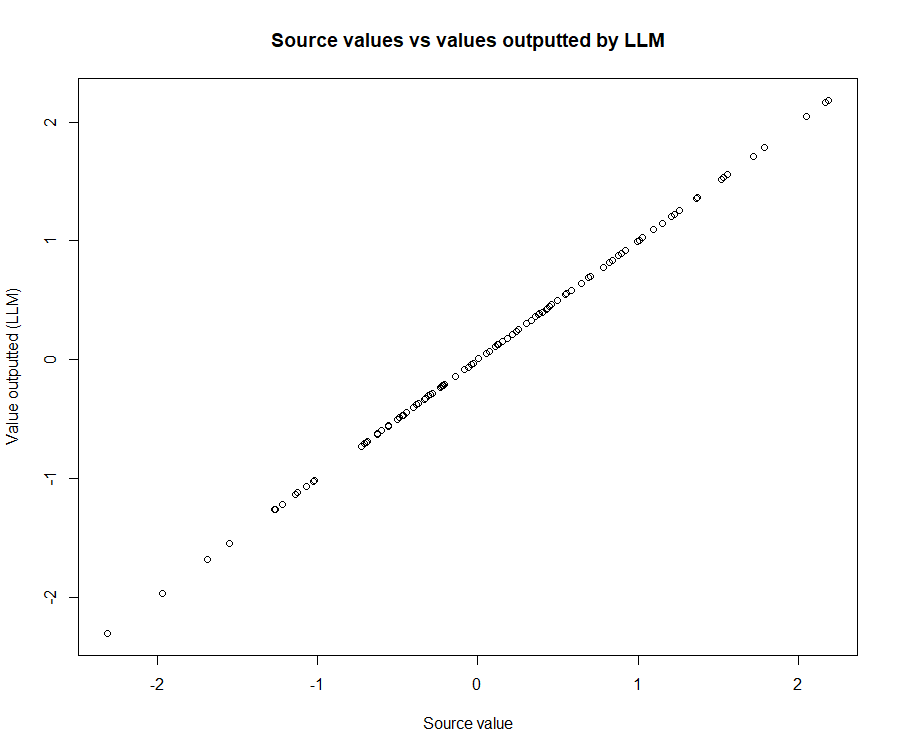
#calculate the difference dta_rnorm<-dta_rnorm |> mutate(diff=source_data-llm_transcribed ) #Check whether the numbers match: table(dta_rnorm$source_data==dta_rnorm$llm_transcribed) #plot the data series for good measure: plot(x=dta_rnorm$source_data, y=dta_rnorm$llm_transcribed, xlab="Source value", ylab="Value outputted (LLM)", main="Source values vs values outputted by LLM") |
Although this is in no way an efficient way to change the deliminator used in a string, I was surprised to find it took my moderately spec’d laptop around ten seconds to execute the entire script and that the numbers outputted were all correct:
Wrapping up: some final points
If you’re wondering why I’m surprised an LLM would be able to complete this task, it’s because they are notoriously bad at arithmetic. They’re also known to ‘hallucinate’, which I expected might result in it outputting numbers that looked correct, but didn’t match what we provided it with. But, I was wrong on both counts: the model seemed to output exactly what we asked for. This could be attributed to a variety of sources, such as the fact the model might have been trained on coding problems resembling our task, but that’s a problem for another post.
Leave a Reply